
![]()
Triva isn't available right now.
Check out the support page for our phone number and hours
![]()

Tax Year | Actions |
|---|---|
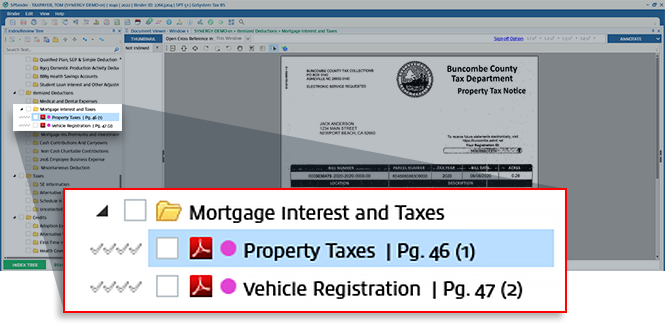
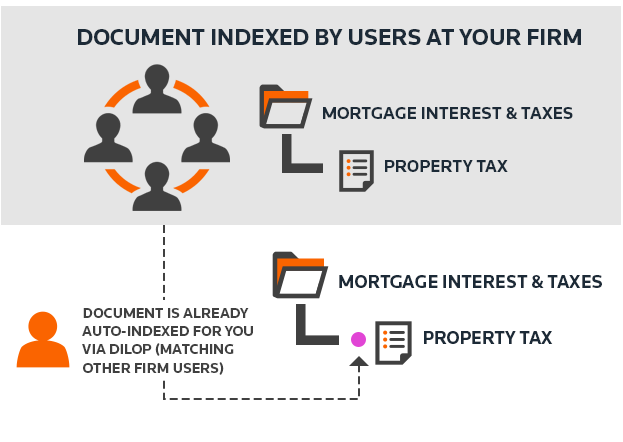
Prior Year (Year 1) | A preparer manually matches (indexes) the document to the desired folder. |
Current Year (Year 2) | DILLY auto-indexes the document to the same folder as last year for the same client - without any manual work from a preparer. |


Binder Type |
|
Tax Client ID (DILLY) | For DILLY, the current year binder's Tax Client ID must be the same as the prior-year Tax Client ID. |
Leadsheets |
|
Services |
|
Tax Software |
|
Binder Submission | The document must go through OCR in order to qualify for DILLY.  |