Oct 22, 2024 | AI
Quick Check Mischaracterization Identification: New Westlaw Enhancement Furthers the Thomson Reuters Generative AI Vision
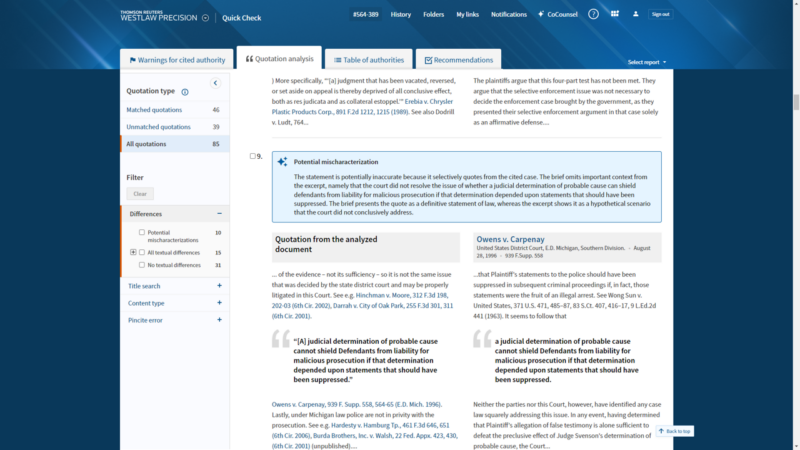
CJ Lechtenberg, senior director, Westlaw Product Management, Thomson Reuters, shares why customers are excited about the latest Quick Check enhancement and how it represents “a new frontier” for leveraging large language models.
Thomson Reuters recently announced deeper integration of CoCounsel 2.0 in Westlaw and Practical Law as well as new generative AI research features – Mischaracterization Identification in Quick Check and AI Jurisdictional Surveys – that are saving customers significant time and helping them ensure accuracy of their research. The enhancements build on the Thomson Reuters vision to deliver a comprehensive GenAI assistant for every professional it serves.
Below, CJ Lechtenberg, senior director, Westlaw Product Management, Thomson Reuters, shares her insights on developing Mischaracterization Identification, a generative AI capability to help detect mischaracterizations and omissions in legal briefs.
In the five years since Quick Check was introduced, you’ve added many enhancements including Quick Check Contrary Authority Identification, Quick Check Judicial and Quick Check Quotation Analysis. How did integrating generative AI make the Mischaracterization Identification enhancement different than previous ones?
Lechtenberg: This enhancement takes researchers beyond the step of knowing what might be a potential mischaracterization to an explanation of why something might be a potential mischaracterization – and that is radically different from any feature we’ve deployed in Quick Check before.
I’m sure it’ll come as no surprise when I say that generative AI is just a completely different beast. Lay people may think about the law as being black and white. You can do this; you can’t do that. But legal professionals know that the law is really a sea of varying shades of gray. With machine learning, we wrestled with how we could ever give the machine enough data to figure out all the different ways an attorney may mischaracterize the law.
In Quick Check Quotation Analysis prior to the Mischaracterization Identification enhancement, we highlighted the actual textual differences – additions, omissions, and changes – in the quotations and showed the context around the quotes. Doing so certainly saved researchers a significant amount of time and helped them spot issues they might not otherwise find, but the onus was still on researchers to review everything and determine what the precise differences were and how material they might be, if at all. Even with the additional context provided, it could still be difficult to determine whether the quotations were taken out of context, especially if the quotes themselves didn’t appear to be different.
In developing Mischaracterization Identification, we recognized that the task of analyzing quotations and their context is so nuanced that attorneys will have different expectations for whether a mischaracterization occurred, so we needed to provide more than just categorizations. We found that large language models (LLMs) can generate nuanced descriptions of potential mischaracterizations, versus just explicit categorizations, and do it well, which is hugely beneficial for this type of task.
How will using Mischaracterization Identification give legal professionals and law firms a competitive advantage? How will judges using it benefit?
Lechtenberg: The advantages of using the new Mischaracterization Identification are substantial for both legal professionals and the judiciary – both in terms of speed of review and quality of work product. When we launched Quick Check Quotation Analysis in 2020, customers, both legal professionals and the judiciary, lamented about how time-consuming it is for them to review quotations and how challenging it is to spot differences. It is a mentally taxing task and often our brains fill in the blanks – interpreting what we think a brief maybe should say but actually doesn’t. Attorneys never have a surplus of time, so the last thing they want to do is spend the little bit they have on the most tedious of tasks and still end up missing potential problems.
For attorneys, Mischaracterization Identification will help them efficiently and accurately make contextual misstatement and omission determinations for their opponents’ and their own quotations and the context surrounding those quotations. The fear of missing their own mistakes is very real for attorneys, but the possibility of missing the opportunity to capitalize on their opponents’ mistakes is an even larger concern. This new enhancement reduces both of those worries and will help attorneys be even better advocates for their clients.
Judges will also be able to effectively review the filings of parties in matters before them much faster. Attorneys owe a duty of candor to the judiciary and the Mischaracterization Identification feature will help flag any potential issues quickly. An added benefit, which members of the judiciary or their staff perhaps haven’t considered, is the ability to analyze their own orders and opinions to ensure that they haven’t made mistakes that could be appealed. This new enhancement will help alert judges and law clerks to potential issues before they finalize their opinions.
What early feedback are you hearing from customers?
Lechtenberg: In a recent survey, 93% of law firm professionals told us they’ve seen opposing counsel misuse a quotation, 66% said they’ve seen misrepresentations by an associate or colleague, and 65% of corporate respondents said they check the accuracy of outside counsel’s quotations. The need to review opposing counsels’ and colleagues’ briefs for mischaracterizations of the law is still a very real issue for attorneys. Likewise, attorneys have said they’re always concerned about the accuracy of their work and that maintaining their reputation as a credible litigator with courts and opposing counsel is incredibly important.
Customers are extremely excited about this new Quick Check enhancement to help combat these concerns and we’ve received positive feedback from them. One law firm managing partner stated that they would use this tool a lot. They cite-check their opponents’ briefs, so any shortcuts are beneficial to them. They recognize that most of the time, errors are harmless, but occasionally there are things they want to bring to the court’s attention and this feature will help them spot those issues more quickly and accurately.
Another law firm partner said this new feature is the “ultimate security blanket” because everything attorneys do is based on their credibility, and this feature alerting them to quotes being taken out of context before filing with the court would calm some of those fears.
Any surprising or unexpected moments as the team worked on developing or launching Mischaracterization Identification?
Lechtenberg: The fact that we’ve accomplished this now with the use of LLMs is exciting, a little surprising and a long time coming. I’m an attorney who leads a team of attorneys; we’re literally trained to question everything and have a healthy dose of skepticism. But I have been dreaming about a mischaracterization identification feature in Quick Check ever since we developed Quotation Analysis more than five years ago. At my core, I believed someday this could be achieved, but for years traditional machine learning approaches were just not powerful or nuanced enough to do it well.
Leveraging LLMs for a use case like this is a new frontier like we’ve never seen before. The LLM’s ability to analyze text from an uploaded document and compare that text to the text from the cited case used to support the argument and then go beyond highlighting textual differences and provide an actual explanation of what may be problematic – whether that’s a selective quote, omitted context or a misinterpreted holding – has been absolutely astounding.
What’s the one thing you want everyone to know about Mischaracterization Identification?
Lechtenberg: Mischaracterization Identification will not only help researchers spot contextual misstatements and omissions in their opponents’ or their own quotations and contextual statements faster and with more accuracy, but most importantly it will help them understand why those misstatements or omissions may be problematic. And, spoiler alert: Mischaracterization Identification is just the beginning of how Thomson Reuters will harness the power of generative AI in Quick Check to solve important customer problems.
For more on Mischaracterization Identification, read the press release or check out the LinkedIn post by Mike Dahn, head of Westlaw Product Management, Thomson Reuters.


