Jan 21, 2025 | innovation
The Rise of Large Language Models in Automatic Evaluation: Why We Still Need Humans in the Loop

In recent years, the field of Natural Language Processing (NLP) has seen remarkable advancements, primarily driven by the development of Large Language Models (LLMs) such as GPT-4, Gemini, and Llama. These models, with their astounding generation capabilities, have transformed a wide range of applications from chatbots to content generation. One exciting and increasingly prevalent application of LLMs is in the automatic evaluation of Natural Language Generation (NLG) tasks. However, while LLMs offer impressive potential for evaluating domain-specific tasks, the necessity for a human-in-the-loop remains essential.
The Emergence of LLMs in Automatic Evaluation
Traditional evaluation metrics in NLG primarily rely on comparing the generated text to reference texts using word overlap measures. These metrics, while useful, often fall short of capturing the nuances of language quality, coherence, and relevance. For example, suppose we have a reference summary “The cat is on the mat.” and a generated summary from a model “A feline is resting on a rug.”. If we use ROUGE as a metric for the evaluation, ROUGE only considers lexical overlap and cannot capture the semantic similarity between words or phrases. These summaries have the same meaning but would score poorly on ROUGE due to low word overlap.
LLMs have demonstrated an exceptional understanding of language, context, and semantics, making them attractive candidates for evaluating generated text. They can assess factors like fluency, coherence, and even factual accuracy, which are crucial for more sophisticated and context-aware evaluations. For instance, LLMs can be fine-tuned to understand the specific jargon and style of a particular domain, such as medical or legal texts, making them great potential evaluators.
The Promise of LLMs in Automated Evaluation
The recent technological advancements of LLMs have encouraged the development of LLM-based evaluation methods in various tasks and systems. LLMs can offer several advantages in the evaluation of NLG tasks:
- Context-Aware Evaluation: Unlike traditional metrics, LLMs can comprehend the context and generate evaluations that account for the subtleties and intricacies of human language.
- Scalability: LLMs can evaluate large volumes of text quickly and consistently, offering scalability that human evaluators cannot match.
- Reduced Subjectivity: Automated evaluation can minimize the subjective bias that human evaluators might introduce, leading to more consistent and objective assessments.
How to use LLM as an Evaluator
LLM-based evaluators are conceptually much simpler than traditional automatic evaluators for evaluation. While traditional evaluation methods rely on predefined metrics and comparisons to reference datasets, LLM-based evaluators work by directly assessing the generated text.
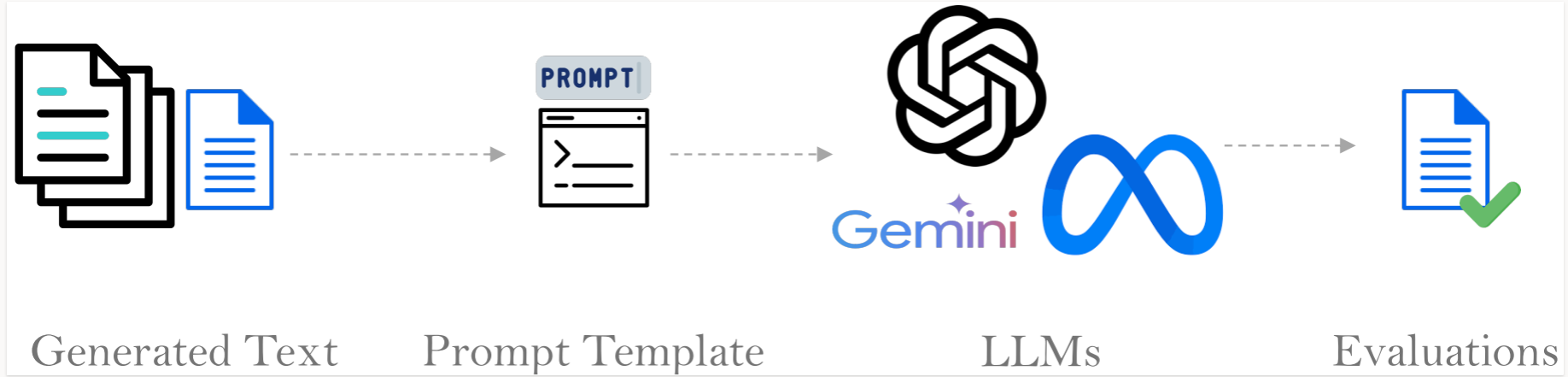
Figure 1 shows an overview of the LLM-based evaluation frameworks. To evaluate the quality of the text, you embed it into a prompt template that contains the evaluation criteria, then provide this prompt to an LLM. The LLM then analyzes the text based on the given criteria and provides feedback on its quality. This approach bypasses the need for extensive preprocessing and reference comparisons, making the evaluation process more straightforward and versatile.

Figure 2 illustrates the step-by-step workflow of evaluating summaries using clarity as a metric. A document and its corresponding summary are inputs. The summary is then embedded into a pre-formulated prompt template that includes detailed evaluation criteria, such as clarity, defined on a 1-to-5 scale. This prompt is then inputted to an LLM for automated analysis and evaluation. Based on the specified criteria, the LLM evaluator reviews the summary, assigns a score, and provides justification for the rating.
The Limitations of LLMs: Why Humans Are Still Indispensable
Despite the promising capabilities of LLMs, there are significant limitations that necessitate the continued involvement of human experts in the evaluation process, especially for domain-specific tasks:
- Lacking Specialized Domain Knowledge: Domain-specific tasks often involve complex knowledge. LLMs are typically trained as general-purpose assistants, and they still lack specialised domain knowledge. In contrast, subject matter experts bring in- depth domain knowledge obtained by years of dedicated training and education.
- Evolving Knowledge: Especially in fast-evolving fields like medicine and technology, staying up-to-date with the latest information is challenging for static models. Human experts, however, continuously learn and adapt to new knowledge and standards.
- Handling Ambiguities: In specialized domains, the language can be highly ambiguous and complex, and the ability to disambiguate based on deep contextual knowledge is something LLMs still struggle with.
- Ethical and Bias Concerns: LLMs can inadvertently reinforce biases present in their training data. Human oversight is crucial to identify and mitigate these biases, ensuring fair and ethical evaluations.
The Human-in-the-Loop Model: Best of Both Worlds
To harness the strengths of LLMs while addressing their limitations, a human-in-the-loop approach is essential. This combines the efficiency and scalability of LLMs with the expertise and judgment of human evaluators:
- Initial Screening: LLMs can perform initial screenings and provide preliminary evaluations, identifying clear cases of high or low quality.
- Expert Review: Human experts then review and refine these evaluations, focusing on cases that require nuanced understanding or where the LLM’s assessment is inadequate.
- Continuous Feedback Loop: Feedback from human evaluators can be used to fine-tune and improve LLMs, creating a continuous improvement cycle.
Conclusion
The integration of LLMs into the automatic evaluation of NLG tasks marks a significant step forward in the field of NLP. However, for domain-specific evaluations, the complexity and nuance of human language still necessitate human experts. By adopting a human-in- the-loop approach, we can leverage the best of both worlds: the speed and scalability of LLMs and the depth and discernment of human evaluators. This constructive interaction ensures that we maintain high standards of accuracy, fairness, and relevance in evaluating natural language generation tasks, ultimately driving the field towards more sophisticated and reliable applications.
This post was written by Grace Lee, lead applied scientist at Thomson Reuters Labs (TR Labs).
Note. This work has been done as part of the internship of Hossein A. (Seed) Rahmani at Thomson Reuters Labs (TR Labs).


